Yapay zekâ artık finansal analiz süreçlerinde yalnızca yardımcı bir teknoloji değil, karar destek mekanizmalarının önemli bir parçası haline geldi. Şirketlerin finansal sağlığını değerlendirmek, finansal sıkıntı riskini tahmin etmek, kredi kararlarını desteklemek ya da denetim süreçlerinde riskli alanları belirlemek için makine öğrenmesi modellerinden giderek daha fazla yararlanılıyor.
Ancak burada kritik bir soru ortaya çıkıyor:
Bir model doğru tahmin yapıyorsa ama bu tahmini neden yaptığını açıklayamıyorsa, ona ne kadar güvenebiliriz?
Finans gibi güven, şeffaflık ve hesap verebilirlik gerektiren bir alanda bu soru son derece önemlidir. Çünkü finansal kararlar yalnızca teknik doğrulukla değil, aynı zamanda izah edilebilirlik ve denetlenebilirlik ile de anlam kazanır.
Doğru Tahmin Yetmez, Açıklama da Gerekir
Random Forest gibi makine öğrenmesi modelleri, yüksek boyutlu finansal veriler üzerinde oldukça başarılı sonuçlar üretebilir. Çok sayıda finansal oranı aynı anda değerlendirerek şirketlerin finansal durumuna ilişkin güçlü tahminler yapabilirler.
Fakat bu modellerin önemli bir dezavantajı vardır: Karmaşıktırlar.
Bir Random Forest modeli, yüzlerce karar ağacının birlikte çalışmasıyla sonuç üretir. Bu yapı tahmin performansını artırır; ancak modelin hangi değişkenlere dayanarak karar verdiğini anlamayı zorlaştırır. Başka bir ifadeyle model güçlüdür, fakat çoğu zaman “kara kutu” gibi davranır.
Bu durum özellikle denetim, regülasyon, kredi değerlendirme ve stratejik karar destek sistemleri açısından önemli bir engeldir. Çünkü bu alanlarda kararın kendisi kadar, kararın gerekçesi de önemlidir.
Çalışmanın Temel Amacı
Bu çalışmada amaç, finansal oranlara dayalı güçlü bir makine öğrenmesi modelinin karar mekanizmasını daha anlaşılır hale getirmektir.
Bunun için küçük ve orta ölçekli işletmelere ait finansal veriler kullanılarak Random Forest modeli eğitilmiş, ardından bu modelin karar yapısını sadeleştirmek ve açıklanabilir hale getirmek için üç farklı yöntem uygulanmıştır:
Most Representative Tree, Random Forest içindeki tüm karar ağaçları arasından, ormanın genel davranışını en iyi temsil eden tek bir ağacı seçer.
Surrogate Tree, karmaşık modelin kararlarını taklit eden daha basit bir karar ağacı oluşturur.
Groves yöntemi ise tüm model yerine, modele en çok benzeyen birkaç karar ağacını seçerek daha küçük ve anlaşılır bir yapı kurar.
Bu yöntemlerin ortak amacı şudur: Modelin tahmin gücünü mümkün olduğunca korurken, karar sürecini insan tarafından anlaşılabilir hale getirmek.
Kullanılan Veri ve Modelleme Yaklaşımı
Çalışmada 503 küçük ve orta ölçekli işletmeye ait bilanço verilerinden türetilen 233 finansal oran kullanılmıştır. Bu oranlar şirketlerin finansal sağlığını değerlendirmek ve sınıflandırmak amacıyla modele verilmiştir.
İlk aşamada Random Forest modeli eğitilmiştir. Model, finansal oranlar arasındaki karmaşık ilişkileri yakalayarak yüksek performans göstermiştir. Ancak çalışmanın asıl katkısı, yalnızca başarılı bir tahmin modeli oluşturmak değildir.
Asıl katkı, bu güçlü fakat karmaşık modelin daha sade, yorumlanabilir ve açıklanabilir versiyonlarını üretmektir.
Random Forest: Güçlü Ama Karmaşık
Random Forest modeli en yüksek performansı veren model olmuştur. Çalışmada modelin doğruluk değeri yaklaşık yüzde 92,5 seviyesine ulaşmıştır. Bu sonuç, modelin finansal oranlar üzerinden şirketlerin finansal durumunu başarılı şekilde sınıflandırabildiğini göstermektedir.
Ancak bu performansın bir bedeli vardır: Modelin karar mekanizmasını doğrudan anlamak kolay değildir.
Yüzlerce karar ağacından oluşan bir modelin hangi finansal göstergelere ne ölçüde önem verdiğini açıklamak, özellikle teknik olmayan paydaşlar için oldukça zordur. Bir denetçi, finansal analist ya da düzenleyici kurum temsilcisi açısından bu durum modelin pratik kullanımını sınırlandırabilir.
Bu nedenle ikinci aşamada model sadeleştirme yöntemleri uygulanmıştır.
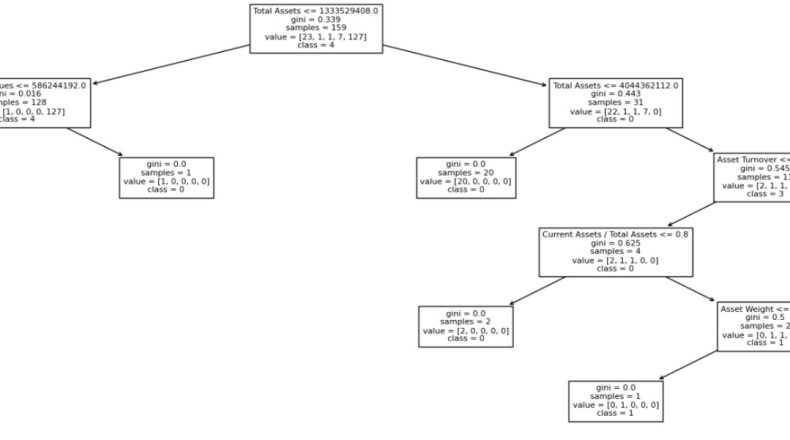
Most Representative Tree: Ormanı Temsil Eden Tek Ağaç
Most Representative Tree yaklaşımı, Random Forest içindeki karar ağaçları arasından tüm modelin genel davranışına en çok benzeyen ağacı seçer.
Bu yaklaşımın en önemli avantajı, karmaşık bir modelin karar mantığını tek bir karar ağacı üzerinden inceleme imkânı sunmasıdır. Böylece kullanıcı yüzlerce ağacı analiz etmek zorunda kalmaz. Modelin hangi finansal oranlar üzerinden ayrım yaptığı daha açık biçimde görülebilir.
Çalışmada Most Representative Tree yöntemi, Random Forest modeline yakın bir performans göstermiştir. Bu da tek bir temsilî karar ağacının, tüm modelin davranışını belirli ölçüde yansıtabileceğini göstermektedir.
Bu yöntem özellikle açıklanabilirliğin kritik olduğu finansal denetim ve karar destek süreçleri için değerlidir.
Surrogate Tree: Karmaşık Modeli Basit Bir Modelle Açıklamak
Surrogate Tree yaklaşımı, Random Forest modelinin kararlarını taklit eden yeni ve daha basit bir karar ağacı oluşturur.
Burada dikkat çekici nokta şudur: Surrogate Tree doğrudan orijinal sınıf etiketlerinden değil, Random Forest modelinin ürettiği tahminlerden öğrenir. Yani bu model, asıl modelin karar verme biçimini yaklaşık olarak taklit etmeye çalışır.
Bu sayede karmaşık modelin karar sınırları daha okunabilir bir yapıya dönüştürülür. Performans Random Forest’a göre bir miktar düşse de, modelin nasıl karar verdiğini anlamak çok daha kolay hale gelir.
Finansal sistemlerde bu tür açıklama modelleri oldukça önemlidir. Çünkü kararın doğruluğu kadar, kararın hangi mantıkla verildiği de sorgulanabilir olmalıdır.
Groves Yöntemi: Az Sayıda Ağaçla Daha Sade Bir Model
Groves yöntemi, Random Forest içindeki en temsilî birkaç karar ağacını seçerek daha küçük bir model oluşturur. Bu çalışmada, orijinal modelin kararlarıyla en yüksek uyumu gösteren üç ağaç seçilmiş ve bu ağaçların çıktıları çoğunluk oylamasıyla birleştirilmiştir.
Sonuçlar, yalnızca üç karar ağacından oluşan bu sade yapının güçlü bir performans sunduğunu göstermiştir. Bu yaklaşım, model karmaşıklığını ciddi ölçüde azaltırken yorumlanabilirliği artırmaktadır.
Başka bir ifadeyle, yüzlerce ağaçtan oluşan bir model yerine, dikkatle seçilmiş birkaç karar ağacıyla benzer karar davranışı elde etmek mümkündür.
Bu da finansal yapay zekâ sistemlerinde daha anlaşılır, daha denetlenebilir ve daha uygulanabilir modeller geliştirme açısından önemli bir bulgudur.
Hangi Finansal Göstergeler Daha Etkili?
Çalışmada modelin hangi finansal değişkenlere daha fazla önem verdiği de analiz edilmiştir. Random Forest modeli, Gini importance ve permutation importance gibi yöntemlerle incelenmiştir.
Öne çıkan finansal göstergeler arasında özkaynak, kısa vadeli yükümlülükler, toplam varlıklar, banka kredileri, net sabit kıymetler, dönen varlıklar, yatırım faaliyetlerinden nakit akışı ve net banka borcu gibi kalemler yer almaktadır.
Bu sonuçlar, modelin finansal sağlık değerlendirmesinde yalnızca tek bir göstergeye değil; varlık yapısı, borçluluk, likidite ve sermaye yapısı gibi farklı boyutlara birlikte baktığını göstermektedir.
Bu tür değişken önem analizleri, modelin finansal mantığını anlamak açısından oldukça değerlidir. Çünkü kullanıcı yalnızca modelin sonucunu değil, sonuca etki eden temel finansal faktörleri de görebilir.
Açıklanabilir Yapay Zekâ Finans İçin Neden Kritik?
Finansal karar sistemlerinde yapay zekânın yaygınlaşması için güven şarttır. Güvenin oluşması için de modelin kararlarını açıklayabilmesi gerekir.
Bir şirketin finansal açıdan riskli sınıflandırıldığını düşünelim. Bu durumda ilgili paydaşlar şu sorulara cevap arar:
Model bu kararı hangi finansal göstergelere dayanarak verdi?
Borçluluk mu daha etkili oldu?
Varlık yapısı mı belirleyici oldu?
Likidite göstergeleri mi risk sinyali verdi?
Eğer model bu sorulara anlaşılır cevaplar sunamıyorsa, tahmin performansı yüksek olsa bile karar süreçlerinde kullanılması zorlaşır.
Bu nedenle açıklanabilir yapay zekâ, finansal teknolojilerde yalnızca teknik bir araştırma konusu değildir. Aynı zamanda regülasyon, denetim, kurumsal güven ve operasyonel uygulanabilirlik açısından da temel bir ihtiyaçtır.
Sonuç: Güçlü Modeller Daha Anlaşılır Hale Getirilebilir
Bu çalışma, finansal oranlara dayalı makine öğrenmesi modellerinde açıklanabilirliğin artırılabileceğini göstermektedir. Random Forest gibi güçlü fakat karmaşık modeller, Most Representative Tree, Surrogate Tree ve Groves gibi yöntemlerle daha sade ve yorumlanabilir yapılara dönüştürülebilir.
Elde edilen sonuçlar, model sadeleştirme yöntemlerinin tahmin performansından büyük ölçüde ödün vermeden açıklanabilirliği artırabileceğini göstermektedir.
Bu yaklaşım özellikle finansal denetim, regülasyon, kredi risk analizi ve karar destek sistemleri için önemli bir potansiyel taşımaktadır.
Gelecekte bu tür açıklanabilir modellerin homomorfik şifreleme, diferansiyel gizlilik ve federated learning gibi mahremiyet koruyucu makine öğrenmesi yöntemleriyle birleştirilmesi mümkündür. Böylece hem güvenli hem açıklanabilir hem de regülasyonlara uyumlu finansal yapay zekâ sistemleri geliştirilebilir.
Finans alanında yapay zekânın gerçek anlamda benimsenebilmesi için yalnızca doğru tahmin yapan modeller yeterli değildir. Kararını açıklayabilen, denetlenebilen ve güven veren modellere ihtiyaç vardır.
Çalışmanın tam hali: https://ieeexplore.ieee.org/abstract/document/11206812/